2026 年 02 月 22 日
LLM 是如何变成 Agent 的?以及其他
#周报
作为将深度学习应用在自动驾驶的工程师,我对深度学习的基本原理掌握的还是很扎实的,但是对于大模型的潜力以及扩展应用总是缺少想象力。很多技术出来后总是让我非常震惊,现在已经进展到这个地步了吗?
过去一个月,我有两次使用 coding agent 的经历。一个是使用 Trae 重新整理了我的个人网页,并且支持了 blog 的更新。这个对我的震撼还不算大,因为我知道我在操作什么,Trae 就是一个非常好用的工具。第二次,是使用 Claude Code 帮老婆跑一些 baseline 实验,整理实验结果。这次给我的震撼就非常大了。具体来说,可能是因为:
- 我配置了 Claude Code 以及 Claude API,从而可以看到 token 的消耗基本上是以 M(百万)为单位。之前我们通过 chatbot 与大模型交互,根本达不到类似使用量。就像是煤油灯与喷气发动机的区别。怪不得大模型的基建都要用千亿美元去砸,不然根本达不到这么大吞吐。
- 我老婆是做通信的,通信领域的东西我一窍不懂。我按照老婆的指示,把她的 paper,rebuttal 文件,全丢给 Claude Code,要跑什么实验,如何统计 metric 全靠模型自己完成。只要最终的指标是在合理的区间内,实验基本上就没有问题。过程中,模型还会针对某些方法在大规模数据上时间复杂度太高做一些针对性优化。这个经历让我彻底被模型的知识广度所折服,整个过程我完全发挥不出什么独有的价值,就是在服务器上起脚本,中断异常的实验。
Agent 虽然是基于 LLM 开发出来的系统,但是他和 LLM 完全不一样,放大了 LLM 的智能,让他的影响力不再局限在文本框中,可以完成几乎一切的数字化任务。
Agent 是如何开发的?一个只能顺序输出文本的 LLM 是如何变成可以处理复杂任务的 Agent 的?
在 agent 底层,我们绕不开 ReAct 框架。ReAct 是 Reasoning 以及 Acting 两个动作的组合。当给定一个 task 时,一个普通的 LLM 的逻辑是直接回答,或者通过 CoT 来增加回答的正确性,但他无法获取外部信息或者操作外部系统。ReAct 框架是通过 thought-action-observation 的循环不断获取新的知识或者一步步完成任务。这里的 action,其实就是预先定义好的接口,Skills,MCP,都可以看作是 action 的约定方式。当 LLM 输出符合约定格式的 action 之后,系统可以解析并且调用对应的 api,完成对应的动作。完成动作得到的反馈信息又会再次加入到 LLM 的 context 中,从而执行下一个迭代。
以 coding 中 debug 一个报错为例,LLM 整个过程可能需要,读取报错信息,读取对应代码片段,写回正确代码片段,执行代码,等若干 action 才能完成对应的任务。
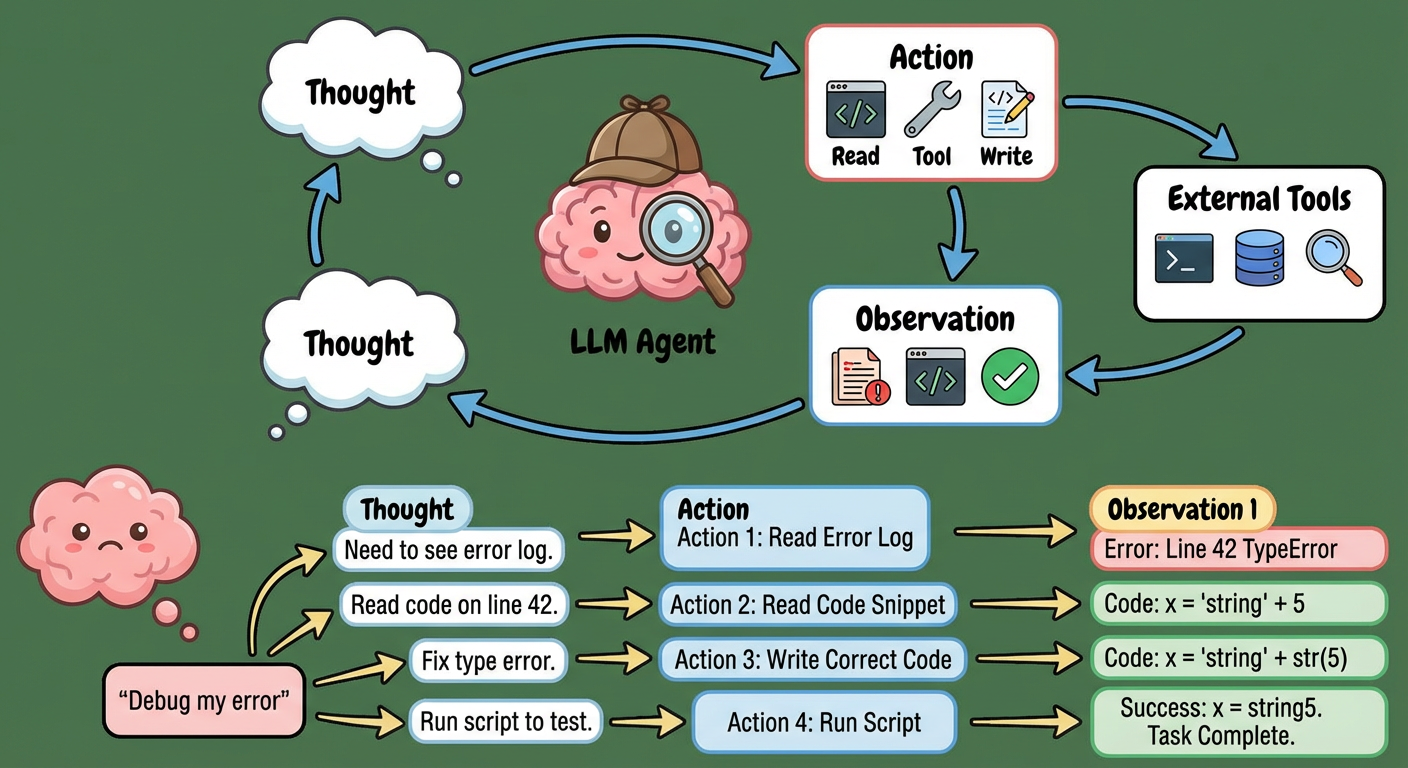
当然,ReAct 还算是一个比较简单的框架,基于上面的框架我们不难衍生出一系列其他的架构。比如引入一个 plan 模型,专门用于顶层规划,先做问题拆分,再交给其他 agent(subagent)来执行,plan 模型不需要知道具体是如何完成的,只需要知道完成是否成功即可。在 plan 的过程中,可以通过思维树的结构,评估不同 plan 的好坏,进而提高其成功的概率。更进一步,将每个 action 执行的结果引入系统的反思过程中,支持重新规划。
以上的改进看起来还是系统思维层面的改进,还有一些工作是通过多个 Agent 协作来完成一个复杂任务,比如 MetaGPT,定义了 product manager,architect, engineer,QA engineer 等角色,将复杂的软件开发拆解定义为一系列可以被简单执行的任务。这样的 Agent 架构,借鉴了人类社会的分工,让一群 agent 可以自主协作,运转。
总得来说,LLM 到 Agent 的蜕变,至少包含了:
- 约定好的 tool use 协议,通过各种外界的工具或者 api,让 LLM 有了眼睛和手。
- 先进的思维方式,如规划,反思,等等。就像查理芒格说的,“你们必须在头脑中拥有一些思维模型。你们必须依靠这些模型组成的框架来安排你的经验,包括间接的和直接的。“
- 通过角色定义而来的合作关系,类似人类分工,不同的 agent 专注于不同的方面,才能把一件复杂的事情执行好。
LLM 是 Agent 系统的引擎,现代的 LLM 迭代也会更加侧重 tool use,planning,等等偏向 agent 的能力迭代。具体来说,需要合成大量的 tool use,api call,问题拆分以及反思的数据,需要在环境中做大规模 rollout 支持 RLVR 的强化学习。
目前 Agent 的发展速度超过了普通用户的学习速度,常常是这个框架还没用明白,更好的框架就已经出来了。学习能力强的人,已经使用 Agent 数十倍放大了自己的产出。就像 Claude Code 的发明人说的,他已经有几个月一行代码也没写,产出效率增加了一倍。Agent 无疑是未来几年快速变革生产力,生产关系的技术。
其他
-
马克的技术工作坊, 128. Manus决定出售前最后的访谈, 飞天闪客 以上的内容,对我理解 agent 的一些细节有帮助。
-
SpaceX has already shifted focus to building a self-growing city on the Moon 面向月球的 milestone 相比火星确实更加现实,Elon 这次画饼 10 年内建造可持续的月球城市,不知道什么时候可以实现。长期看,我对 SpaceX 的工程能力是乐观的,也期望有这样一个灯塔牵引大家持续突破。
-
cosmos-drive-dreams-toolkits 面向自动驾驶世界模型的 condition 编辑器。
-
DreamZero 利用(finetune)视频生成模型来做具身的基座模型。视频生成模型确实是一个非常强的几何理解,场景预测模型。3DV 的领域中,视频生成模型就被微调成了各种深度,重建,新视角合成的数据。相比 VLM -> VLA 的范式,视频生成模型的好处是监督足够稠密,并且能够很好兼容各种机器人本体结构,都是图像输入输出。作为 system-1 的一部分是挺合理的。
-
World-VLA-Loop 我个人理解,将 WM 这样的生成模型,用于补充 VLA 的训练数据。WM 同时生成图像序列以及 reward,可以将稀疏的 VLA 监督数据稠密化,从而提升 VLA 的能力。